大数据时代数据仓库Hive
22 Jan 2022在Hadoop大数据平台及生态系统中,使用mapreduce模型进行编程,对广大用户来说,仍然是具有挑战性的任务。人们希望使用熟悉的SQL语言,对hadoop平台上的数据进行分析处理,这就是SQL On Hadoop系统诞的背景。
SQL on Hadoop是一类系统的简称,这类系统利用Hadoop实现大量数据的管理,具体是利用HDFS实现高度可扩展的数据存储。在HDFS之上,实现SQL的查询引擎,使得用户可以使用SQL语言,对存储在HDFS上的数据进行分析。
Apache Hive的产生
Hive是基于Hadoop的一个数仓工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的类SQL(HQL)查询功能,可以将HQL语句转换成为MapReduce任务进行运行。使用类SQL语句就可快速实现简单的MapReduce统计,不必开发专门的MapReduce应用。Apache Hive是由Facebook开发并开源,最后贡献给Apache基金会。
Hive系统整体3个部分:用户接口、元数据存储、驱动器(Driver)在Hadoop上计算与存储。
- 用户接口主要有
3个,CLI、ThriftServer和HWI。最常用的就是CLI,启动hive命令回同时启动一个Hive Driver。ThriftServer是以Thrift协议封装的Hive服务化接口,可提供跨语言的访问,如Python、C++等,最后一种是Hive Web Interface提供浏览器的访问方式。 - 表结构的一些
Meta信息是存储在外部数据库的,如MySQL、Oracle和Derby库。Hive中元数据包括表的名字、表的列和分区及其属性、表的属性(是否为外部表等)、表的数据所在目录等。 Driver部分包括:编译器、优化器和执行器,编译器完成词法分析、语法分析,将HQL转换为AST。AST生成逻辑执行计划,然后物理MR执行计划;优化器用来对逻辑计划、物理计划进行优化,生成的物理计划转变为MR Job并在Hadoop集群上执行。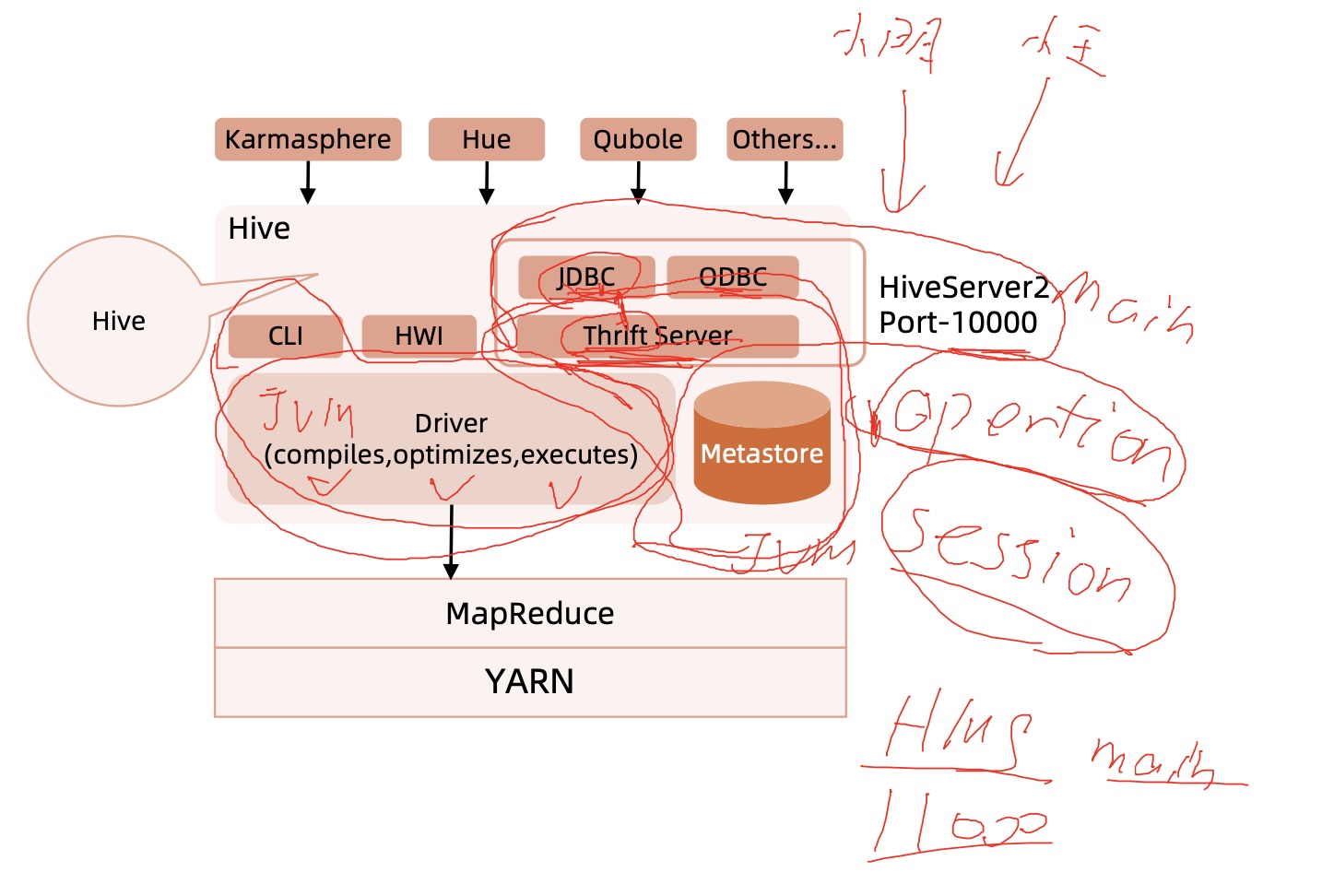
Hive数据模型
Hive通过以下模型来组织HDFS上的数据,包括:数据库DataBase、表Table、分区Partition和桶Bucket。
Table管理表和外表,Hive中的表和关系数据库中的表很类似,依据数据是否受Hive管理可分为:Managed Table(内表)和External Table(外表)。对于内表,HDFS上存储的数据由Hive管理,Hive对表的删除影响实际的数据。外表则只是一个数据的映射,Hive对表的删除仅仅删除愿数据,实际数据不受影响。Partition基于用户指定的列的值对数据表进行分区,每一个分区对应表下的相应目录${hive.metastore.warehouse.dir}/{database_name}.db/{tablename}/{partition key}={value},其优点在于从物理上分目录划分不同列的数据,易于查询的简枝,提升查询的效率。Bucket桶作为另一种数据组织方式,弥补Partition的短板,通过Bucket列的值进行Hash散列到相应的文件中,有利于查询优化、对于抽样非常有效。
Hive的数据存储格式,聊聊Parquet*
Parquet*起源于Google Dremel系统,相当于Dremel中的数据存储引擎。最初的设计动机是存储嵌套式数据,如Protocolbuffer、thrift和json等,将这些数据存储成列式格式,以便于对其高效压缩和编码,且使用更少的IO操作取出需要的数据。并且其存储metadata,支持schema的变更。
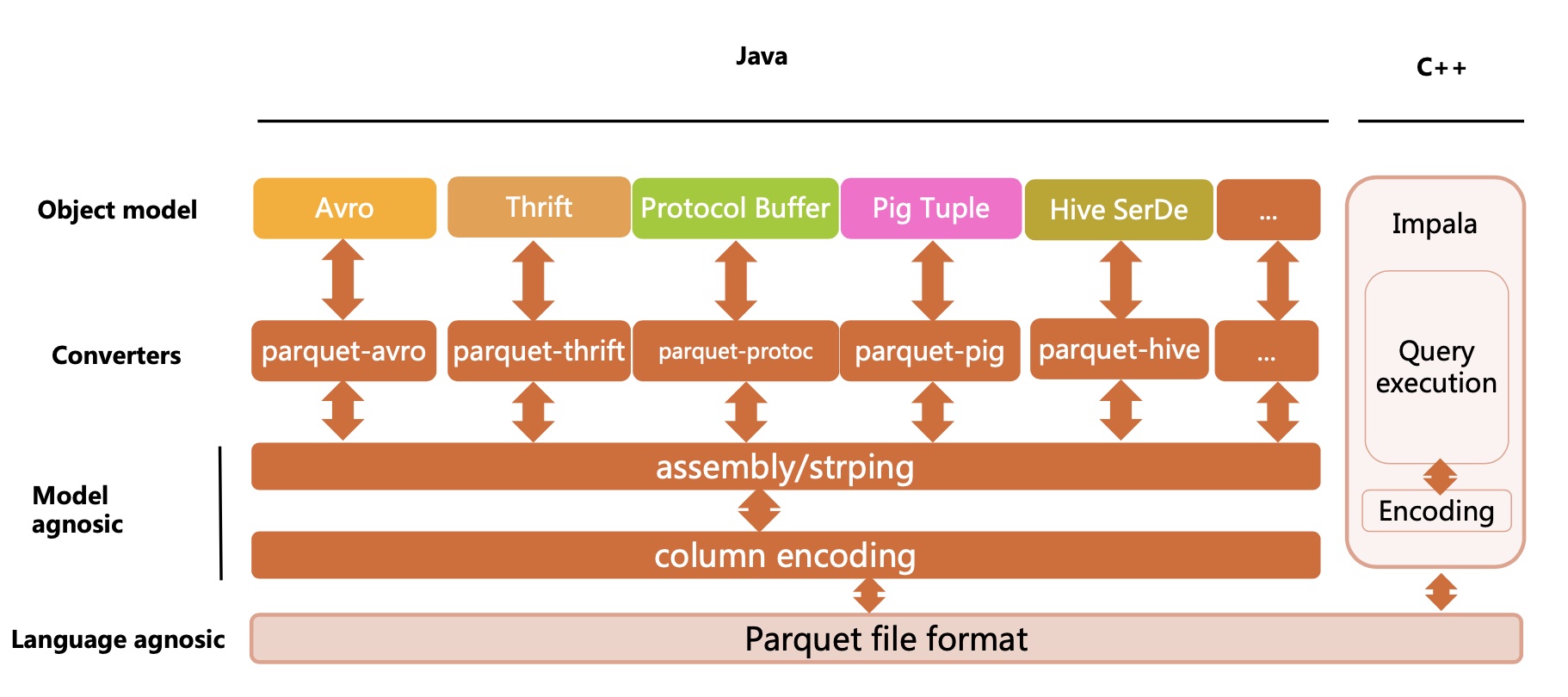
Parquet*是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发。一个Parquet文件通常由一个header和一个或多个block块组成,以一个footer结尾。footer中的metadata包含了格式的版本信息、schema信息、key-value pairs以及所有block中的metadata信息。
parquent-format项目定义了parquent内部的数据类型、存储格式等。parquent-mr项目完成外部对象模型与parquent内部数据类型的映射,对象模型可以简单理解为内存中的数据表示,Avro、Thrift、Protocol Buffers等这些都是对象模型。
Hive Catalog介绍
HCatalog是Hadoop的元数据和数据表的管理系统,它基于Hive中的元数据层,通过类似SQL的语言展现Hadoop数据的关联关系。Catalog允许用户通过Hive、Pig、MapReduce共享数据和元数据,用户编写应用程序时,无需关心数据怎样存储、在哪里存储,避免因schema和存储格式的改变而受到影响。- 通过
HCatalog,用户能通过工具访问Hadoop上的Hive Metastore。它为MapReduce和Pig提供了连接器,用户可以使用工具对Hive的关联列格式的数据进行读写。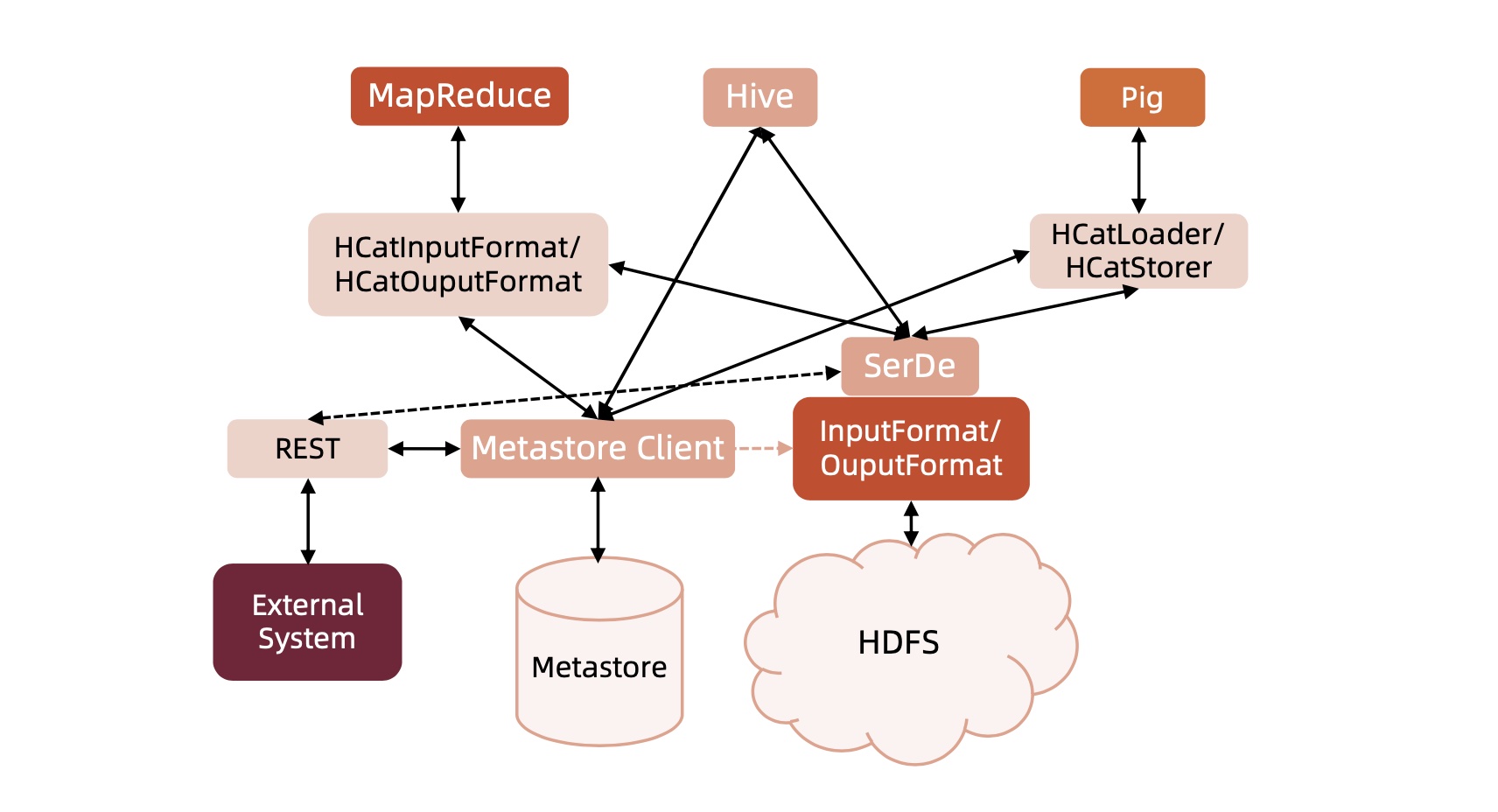
数据类型及数据定义
hive支持基本数据类型有tinyInt、int、bigInt、String等,除此之外,其还支持复杂类型,如struct、map和array等。Hive中默认以\n作为行分割符,以^A用于字段分割符,用^B分割array或struct中的元素,或用于map中键-值对之间的分割,使用^C用于map中键和值之间的分割。
若要实现自定义话,需用一组row format delimited语句,分别指定行、字段、map、list的分割符:
create table employees(
...field list
) row format delimited
fields terminated by `\001`
collection items terminated by `\002`
map keys terminated by `\003`
lines terminated by `\n` stored as textfile;
hive数据表分为管理表和外部表,external表用于加载外部数据源,删除外部表并不会删除hdfs上的文件数据,有些HiveQL语法结构并不适用于外部表。hive中有数据分区的概念,可以看到分区表具有重要的性优势,而且分区表还可以用一种符合逻辑分方式进行组织,比如分层存储。
创建好表之后,可用hsql从hdfs中向hive表加载数据,用overwrite会完全覆盖表中的记录:
LOAD DATA INPATH '/tmp/hive/metastore/financials.db/employees/employee-22-0927.csv' INTO TABLE employees;
UDF和自定义FileFormat
在hive中用户可以自定义实现UDF,对hive库已有的函数进行扩展,例子,自定义UDF实现计算每个人所属的星座功能。实现类UDFZodiacSign继承基类UDF并实现evaluate()函数,在查询中对于每行输入都会应用到evaluate()函数,而evaluate()处理后的值会返回给Hive。
加载hadoop-mapreduce-1.0.0.xx.jar到hive中,只与当前session会话进行了绑定。
hive> add jar /Users/madong/datahub-repository/distributed-data-computing/hadoop-mapreduce/target/hadoop-mapreduce-1.0.0-jar-with-dependencies.jar
将函数zodiac注册到hive中,可以用describe function extended zodiac来查看函数明细内容:
hive> create temporary function zodiac as 'hadoop.apache.hive.UDFZodiacSign';
# 实际执行真正的sql,zodiac(date)将日期转为了对应的星座
hive (financials)> select name, zodiac(bday) from littlebigdata;
OK
name _c1
edward capriolo Aquarius
在使用完UDF后,可以通过drop temporary function if exists zodiac删除此函数。UDAF自定义扩展和UDF一样,但其继承的是GenericUDF类,要想使所有函数都长期有效,可在FunctionRegistry中注册,然后重新替换hive-exec-*.jar这个jar文件就可以。
registrUDF('parse_url', UDFParseUrl.class, false)
registerGenericUDF('nvl', GenericUDFNvl.class)
registerGenericUDF('split', GenericUDFSplit.class)
FileFormat是用自定义的方式从HDFS上读取内容,按指定的格式切分fields以及row数据,实现方式可参考Base64TextInputFormat和Base64TextOutputFormat。
- hive conflient: https://cwiki.apache.org/confluence/display/Hive/DeveloperGuide#DeveloperGuide-RegistrationofNativeSerDes
- base64 fileformat: https://github.com/apache/hive/tree/master/contrib/src/java/org/apache/hadoop/hive/contrib/fileformat