大数据三架马车之Yarn、BigTable
07 Nov 2021在Hadoop V1.0版本中,资源调度部分存在扩展性差、可用性差、资源利用率低的改问题,其中,Job Tracker既要做资源管理,又要做任务监控,同时Job的并发数页存在限制。同时,JobTracker存在单点故障问题,任务调度部分不支持调度流式计算、迭代计算、DAG模型。
2013年,Hadoop 2.0发布,引入了Yarn、HDFS HA、Federation。
Yarn的设计思路(Yet Another Resource Manager)
Yarn由三部分组成:ResourceManager、NodeManager、ApplicationMaster,其中:RM掌控全局的资源,负责整个系统的资源管理和分配(处理客户端请求、启动/监控AM和NM、资源调度和分配),NM驻留在一个YARN集群的节点上做代理,管理单个节点的资源、处理RM、AM的命令,AM为应用程序管理器,负责系统中所有所有应用程序的管理工作(数据切分、为APP申请资源并分配、任务监控和容错)。
Yarn主要解决数据集群资源利用率低、数据无法共享、维护成本高的问题,常见的应用场景有:MapReduce实现离线批处理、Impala实现交互式查询分析、用Strom实现流式计算、在Spark下来完成迭代计算。
Yarn Container及资源调度流程
Container是Yarn资源的抽象,它封装了某个节点上一定量的资源(CPU和内存两类资源),它跟Linux Container没有任何关系,仅仅是Yarn提出的一个概念(可序列、反序列的对象)。
message ContainerProto {
optional ContainerIdProto id = 1; // container id
optional NodeIdProto nodeId = 2; // 资源所在节点
optional string node_http_address = 3;
optional ResourceProto resource = 4; // container资源量
optional PriorityProto priority = 5; // container优先级
optional hadoop.common.TokenProto container_token = 6;
}
Container由ApplicationMaster向ResourceManager申请的,由ResourceManager中的资源调度器异步分配给ApplicationMaster。Container的运行是由ApplicationMaster向资源所在的NodeManager发起的,Container运行时需提供内部执行的任何命令(比如Java、Python、C++进程启动命令均可)及该命令执行所需的环境变量和外部资源。
资源调度算法及调度器
调度算法是整个资源管理系统中一个重要的部分,简单地说,调度算法的作用是决定一个计算任务需要放在集群中的哪台机器上面。待调度的任务需考虑资源需求(CPU、Memory、Disk),应用亲和及反亲和性等。
FIFO调度,先来的先被调用、分配CPU、内存等资源,后来的在队列等待。适用于平均计算时间、耗时资源差不多的作业,通常还可匹配优先级,不足在于用户将Job作业优先级设置的最高时,会导致排在后面的短任务等待。SJF(Shortest Job First)调度,为了改善FIFO算法,减少平均周转时间,提出了短作业优先算法。任务执行前预先计算好其执行时间,调度器从中选择用时较短的任务优先执行,但优先级无法保证。- 时间片轮转调度
(Round Robin,RR),核心思想是CPU时间分片(time slice)轮转就绪任务,当时间片结束时,任务未执行完时发生时钟中断,调度器会暂停当前任务的执行,并将其置于就绪队列的末尾。此调度优点在于跟任务大小无关,都可获得公平的资源分配。但实现较为复杂,计算框架需支持中断。 - 最大最小公平调度(
Min-Max Fair),将资源平分为n份(每份S/n),把每份分给相应的用户。若超过了用户的需求,就回收超过的部分,然后将总体回收的资源平均分给上一轮分配中尚未得到满足的用户,直到没有回收的资源为止。 - 容量调度(
Capacity),首先划分多个队列,队列资源采用容量占比的方式进行分配。每个队列设置资源最低保证和使用上限。如果队列中的资源有剩余或空闲,可暂时共享给那些需要资源的队列,一旦该队列有新的应用程序需要运行资源,则其它队列释放的资源会归还给该队列。
Yarn的三种调度器实现为:Fair Scheduler(公平调度器)、FIFO Scheduler(先进先出调度器)、Fair Scheduler(公平调度器),FIFO先进先出调度器,同一时间队列中只有一个任务在执行,可以充分利用所有的集群资源。Fair Scheduler和Capacity Scheduler有区别的一些地方,Fair队列内部支持多种调度策略,包括FIFO、Fair、DRF(Dominant Resource Fairness)多种资源类型(e.g.CPU、内存的公平资源分配策略)。
Job提交流程
在yarn上提交job的流程如下方的步骤图所示,yarnRunner向rm申请一个Application,rm返回一个资源提交路径和application_id,客户端提交job所需要的资源(切片+配置信息+jar包)到资源提交路径。
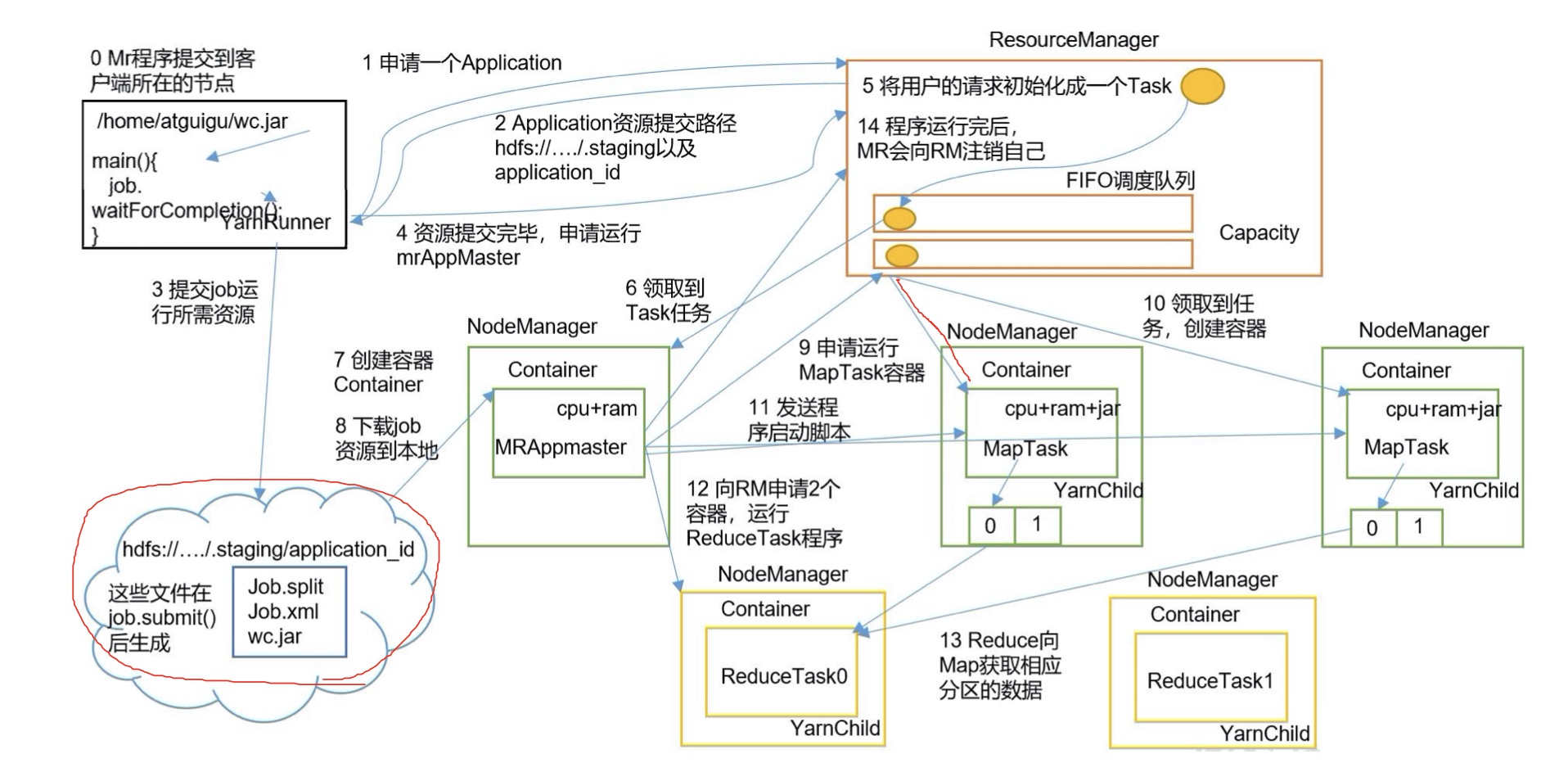
Capacity Scheduler参数调整是在yarn-site.xml中,yarn.resourcemanager.scheduler.class用于配置调度策略org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler。
Yarn的高级特性Node Label,HDFS异构存储只能设置让某些数据(以目录为单位)分别在不同的存储介质上,但是计算调度时无法保障作业运行的环境。在Nodel Label出现之前,资源申请方无法指定资源类型、软件运行的环境(JDK、python)等,目前只有Capacity Scheduler支持此功能,Fair Scheduler正在开发,yarn.node-labels.enable用于开启Node Label的配置。
BigTable的开源实现HBase
BigTable是一个分布式存储系统,用于管理结构化数据,旨在扩展到非常大的规模:数千个商品服务器上的PB级数据。Google的很多项目使用HBase来存储数据,包括:网页索引、google地图和google金融,这些应用程序在数据大小(从URL到网页再到卫星图像)和延迟要求(从后端批量处理到实时数据服务)方面对BigTable提出了不同的要求。
Hbase是一个稀疏的、分布式的、持久的多纬排序图,该映射由行键、列键和时间戳索引组成,map中的每个值都是一个不可序列化的字节数组。其对应的数据模型(逻辑视图)如下:
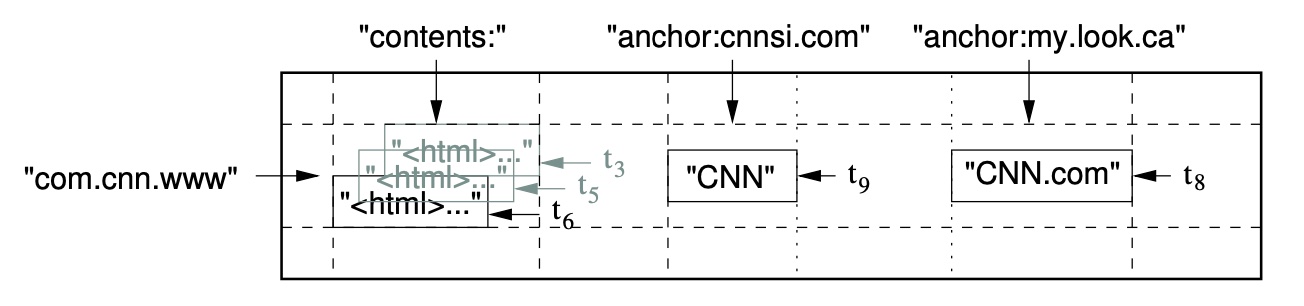
(row:string, column:string, time:int64) -> string
- 行关键字
Row key,唯一标识一行数据,用于检索记录。其可以是任意长度的字符串,最大长度为64KB。存储时会按照row key的字典序进行排序,其可通过单个row key、row key的range及全表扫描的方式来访问。 Column Family,行中的列被成为列族,同一个列族的所有成员具有相同的列族前缀,列键Column Key也称为列名,必须以列族作为前缀,格式为列族:限定词。Timestamp和Cell,插入单元格时的时间戳,默认作为单元格的版本号,类型为64位整数。要定位一个单元,需满足”行键+列键+时间戳”三个要素。
在物理视图上,HBase的每一个列族Column Family对应一个StoredFile对象,服务组件整体分为HMaster和Region Server两部分,底层使用Hadoop的DataNode来存储数据。