大数据三架马车之MapReduce
09 Aug 2021
Hadoop是Apache的一个开源的分布式计算平台,以HDFS分布式文件系统和MapReduce计算框架为核心,为用户提供一套底层透明的分布式基础设施。
MapReduce提供简单的API,允许用户在不了解底层细节的情况下,开发分布式并行程序。利用大规模集群资源,解决传统单机无法解决的大数据处理问题,其设计思想起源于MapReduce Paper。
MapReduce编程模型
MapReduce是一种用于处理和生成大型数据集的编程模型和相关实现,用户指定一个map()函数接收处理key/value对,同时产生另外一组临时key/value集合,reduce()函数合并相同intermediate key关联的value数据,以这种函数式方风格写的程序会自动并行化并在大型商品机器集群上运行。
在Paper发布之前的几年,Jeffrey Dean及Google的一些工程师已经实现了数百个用于处理大量原始数据且特殊用途的计算程序,数据源如抓取的文档、Web日志的请求等,来计算各种派生数据,像倒排索引、Web文档图结构的各种表示、每个主机爬取的页面数汇总等。
看个统计单词在文章中出现的次数的例子,map()函数emit每个单词及其出现次数,reduce()函数统计按单词统计其出现的总次数,伪代码如下:
map(String key, String value):
// key: document name
// value: document contents for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values): // key: a word
// values: a list of counts
int result = 0;
for each v in values: result += ParseInt(v);
Emit(AsString(result));
谈一些MapReduce程序在Google的应用:
- 反向索引(
Inverted Index),map()函数解析文档中的每个单词,对(word, document ID)进行emit,reduce端依据word将二元组pair中的document id进行合并,最终emit(word, list(document ID))的数据。 - 统计
URL的访问频次,map()函数输出从log中获取web request的信息,将(URL, 1)的二元组进行output,reduce()端将具有相同URL的请求进行归集,以(URL, total count)的方式进行emit。 - 反转
Web-Link Graph,map()函数针对网页中存在的超链接,按(target, source)的格式输出二元组,reduce()函数将相同target对应的source拼接起来,按(target, list(source))的方式进行emit。
Execution Overview
在输入数据切分成数份后,map函数会被自动分发到多台机器上,输入数据切分可以在多不同的机器上并行执行。partition()函数(hash(key) mod R)会将中间key切分为R片,reduce()函数会根据切分结果分到不同机器。
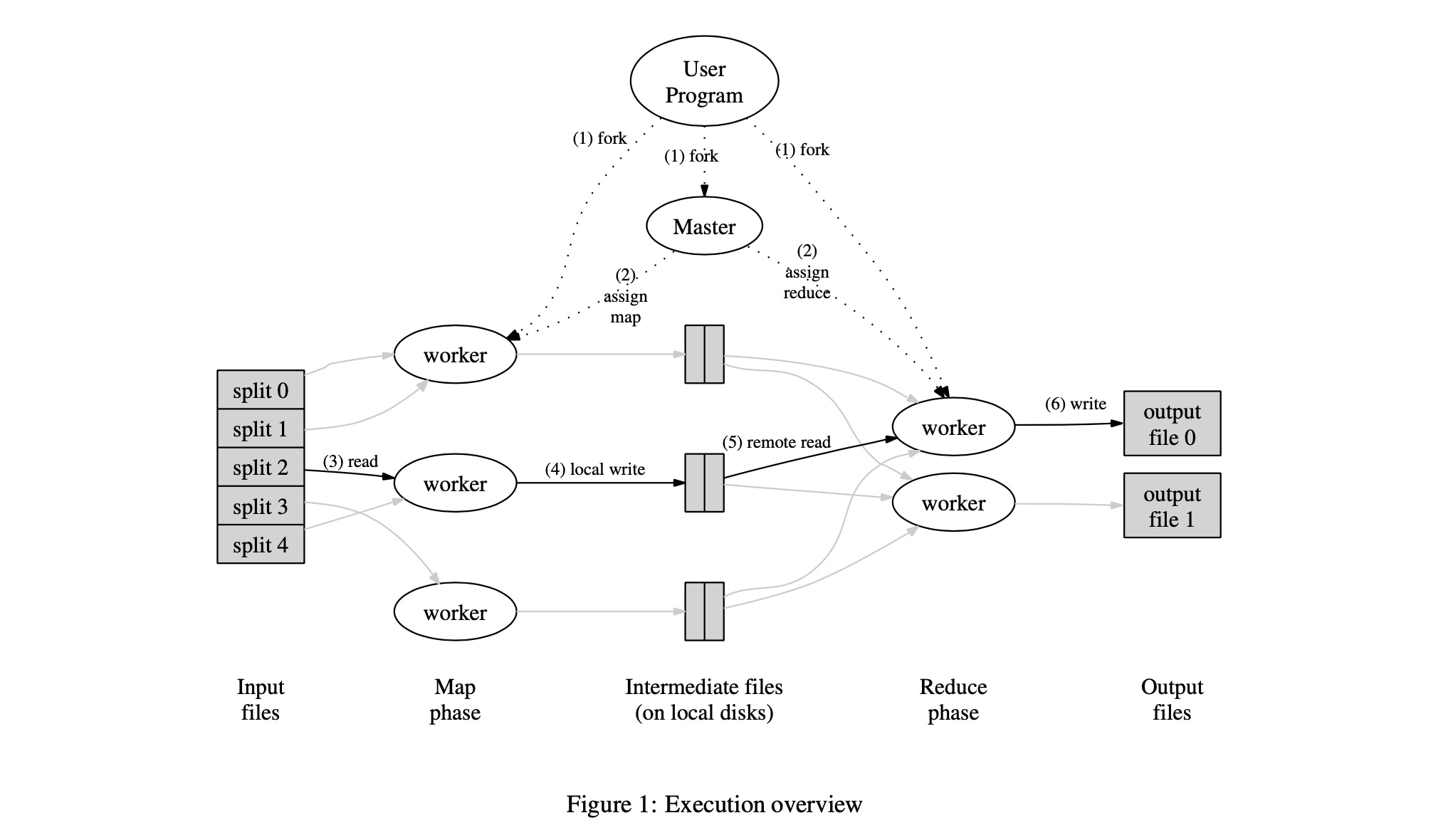
- 用户程序中的
mapreduce library会将输入的文件切分成16MB~64MB的文件块,然后它在cluster中启动多个副本。 - 在
cluster上跑的多个程序中有一个是特殊的,其为master节点,剩余的为worker节点。master节点向worker节点分配任务,当worker节点有空闲时,会向其分配map或reduce任务。 worker执行map任务时,会从切分的文件中读取数据,它从文件中读取key/value对,在map()函数中执行数据处理,生成的intermediate key会缓存在memory中。memory中的pair会定期的写入本地磁盘,并将其位置信息返给master节点,其负责将buffered pair对应的位置信息转发给其它worker节点。- 当
master节点将map函数产生的中间数据位置告知reduce worker时,其会使用rpc从map worker的本地磁盘中读取数据。当reduce worker读完所有数据后,它会对intermediate key对数据进行排序,因此,具有相同key的中间结果就会被group在一起。sort是非常必要的,因为通常情况下,许多不同的key会映射到相同的reduce函数中。当中间数据太大在memory中放不下时,会使用外部排序进行处理。 reduce worker会遍历排序后的中间数据,将intermediate key及对应value集合传给reduce函数,reduce()函数的输出结果会append到一个最终的输出文件中。当所有map和reduce任务都执行完成后,它会告知用户程序返回用户代码。
容错性考虑
由于mapreduce旨在帮助使用成百上千台机器处理处理大量数据,因此该机器必须优雅地容忍机器故障,分别讨论下当worker和master节点故障时,如何进行容错?
worker节点故障,master节点会周期性的ping所有的worker节点,若worker在给定时间内未响应,则master会标记worker为failure状态。此时,该worker节点上已执行完的map task会被重新置为initial idle状态,然后会等待其它worker执行此task。类似的,任何此worker上正在执行的map()或reduce()任务也会被重置为idle状态,然后等待调度。
为什么已经完成的map task还要被重新执行呐?因为map()会将intermediate data写在本次磁盘上,当worker不可访问时,执行reduce()时无法从failure worker中取数据。而completed reduce不需要重新执行,因为reduce()函数已将最终结果写到外部存储HDFS上。
master节点故障问题,容错方案较为简单,就是让master每隔一段时间将data structures写到磁盘上,做checkpoint 。当master节点die后,重新启动一个master然后读取之前checkpoint的数据就可恢复状态。
Input文件切分,Split和Block的区别
split是文件在逻辑上的划分,是程序中的一个独立处理单元,每一个split分配给一个task去处理。而在实际的存储系统中,使用block对文件在物理上进行划分,一个block的多个备份存储在不同节点上。
文件切分算法主要用于确定inputSplit的个数及每个inputSplit对应的数据段,splitSize=max{ minSize, min{totalSize/numSplits, blockSize}},最后剩下不足splitSize的数据块单独成为一个InputSplit。
Host选择算法,Input对象由(file, start, length, hosts)这个四元组构成,节点列表是关键,关系到任务的本地性(locality),mapreduce优先让空闲资源处理本节点的数据。
mapreduce的sort分两种:map task中spill数据的排序,数据写入本地磁盘之前,先要对数据进行一次本地排序(快排算法)。reduce task中数据排序,采用归并排序或小顶堆算法,sort和reduce可同时进行。
MapReduce分布式计算框架
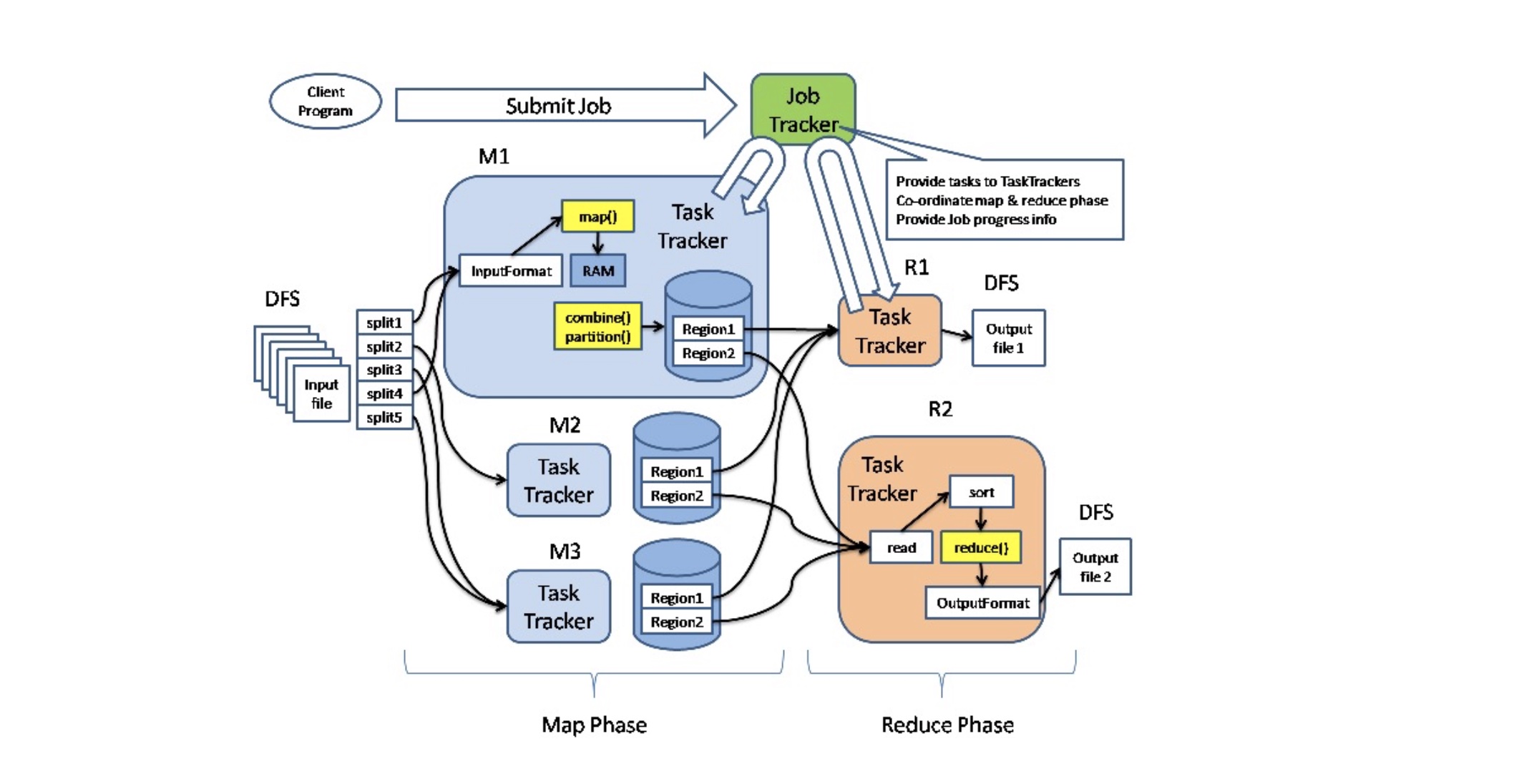
MapReduce核心组件有JobTracker、TaskTracker和Client:
JobTracker负责集群资源监控和作业调度,通过心跳监控所有TaskTracker的健康状况。监控Job的运行情况、执行进度、资源使用,交由任务调度器负责资源分配,任务调度器有FIFO Scheduler和Capacity Scheduler。TaskTracker具体执行Task的单元,以slot为单位等量划分本节点资源,分为MapSlot和ReduceSlot。其通过心跳周期性向JobTracker汇报本节点资源使用情况和任务执行进度,同时接收JobTracker的命令执行相应的操作(启动新任务、杀死任务等)。Client提交用户编写的程序到集群,查看Job的运行状态。
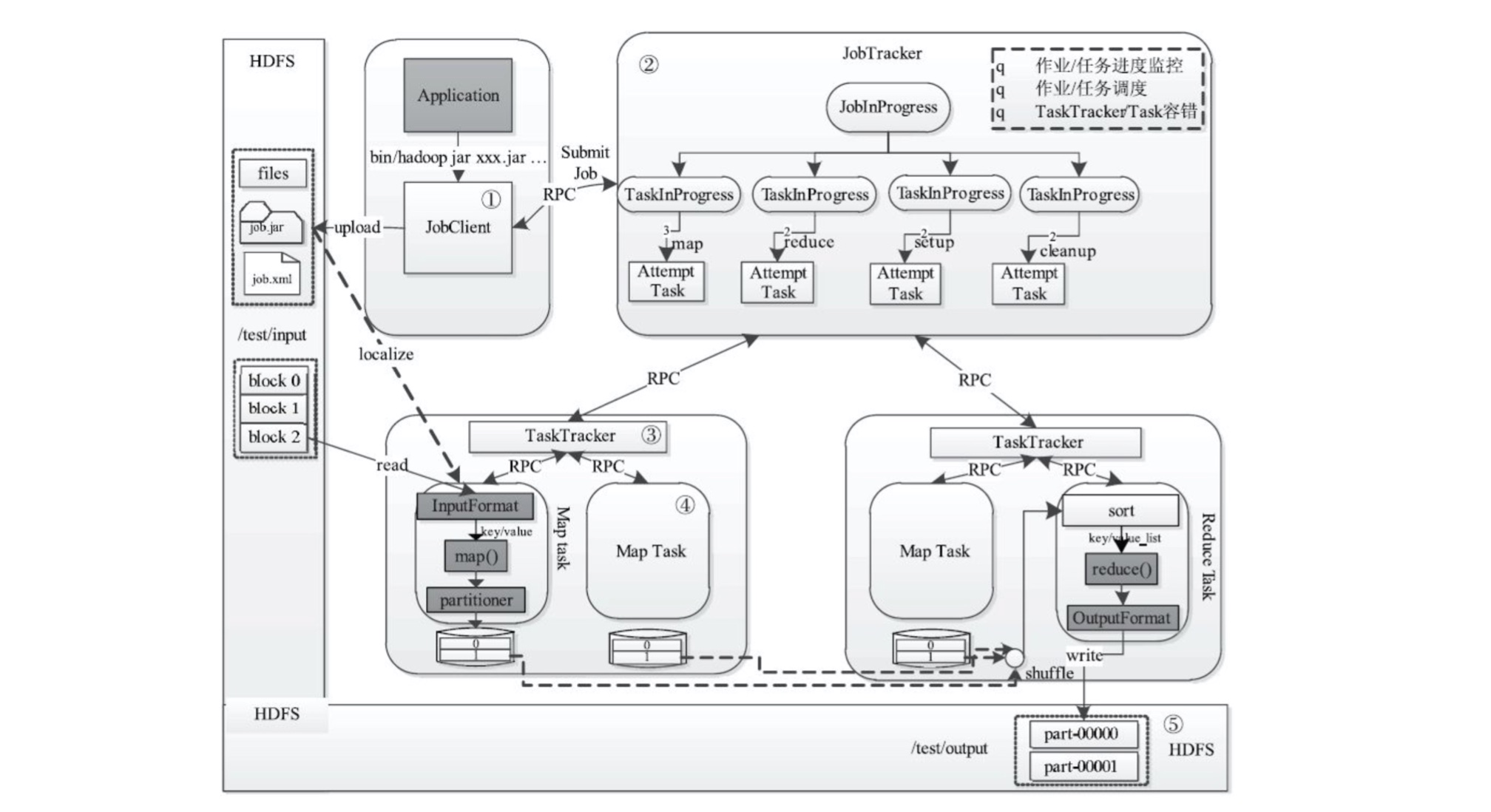
MR Job声明周期文字描述:
- 作业提交和初始化:首先
JobClient将作业相关文件上传到HDFS,然后JobClient通知JobTracker使其对作业进行初始化(JobInProgress和TaskInProgress)。 - 任务调度和监控:
JobTracker的任务调度器按照一定策略(TaskScheduler),将task调度到空闲的TaskTracker。 - 任务
JVM启动,TaskTracker下载任务所需文件,并为每个Task启动一个独立的JVM。 TaskTracker启动Task,Task通过RPC将其状态汇报给TaskTracker,再由TaskTracker汇报给JobTracker。- 完成作业后,会讲数据回写到
hdfs。