大数据的三架马车之HDFS
19 Jul 2021主要介绍HDFS的基本组成和原理、Hadoop 2.0对HDFS的改进、HADOOP命令和基本API、通过读Google File System论文来理解HDFS设计理念。
Hadoop是Apache一个开源的分布式计算平台,核心是以HDFS分布式文件系统和MapReduce分布式计算框架组成,为用户提供了一套底层透明的分布式基础设施。
HDFS是Hadoop分布式文件系统,具有高容错性、高伸缩性,允许用户基于廉价精简部署,构件分布式文件系统,为分布式计算存储提供底层支持。MapReduce提供简单的API,允许用户在不了解底层细节的情况下,开发分布式并行程序,利用大规模集群资源,解决传统单机无法解决的大数据处理问题,其设计思想起源Google GFS、MapReduce Paper。
在Mac上搭建Hadoop单机版环境
从 https://hadoop.apache.org 下载二进制的安装包,具体配置可进行Google。配置完成后,在执行HDFS命令时会提示 Unable to load native-hadoop library for your platform...using buildin-java classes..,运行Hadoop的二进制包与当前平台不兼容。
为解决该问题,需在机器上编译Hadoop的源码包,用编译生成的native library替换二进制包中的相同文件。编译Hadoop源码需安装cmake、protobuf、maven、openssl组件。
$ mvn package -Pdist,native -DskipTests -Dtar
在编译hadoop-2.10.1的hadoop-pipes模块时出现错误,原因是由于openssl的版本不兼容,机器上的是32位,而实际需要64位。最后从github下载openssl-1.0.2q.tar.gz安装包,通过源码安装,并在/etc/profile中配置环境变量:
export OPENSSL_ROOT_DIR=/usr/local/Cellar/openssl@1.0.2q
export OPENSSL_INCLUDE_DIR=/usr/local/Cellar/openssl@1.0.2q/include/
然后重新执行maven命令,hadoop源码编译通过了。最后将hadoop-dist目录下的native包拷贝到hadoop二进制的源码包下就可以了。
Hadoop 1.0架构
GFS cluster由一个master节点和多个chunkserver节点组成,多个GFS client可以对其进行访问,其中每一个通常都是运行用户级服务器进程的商用linux机器。大文件会被分为大小固定为64MB的块。
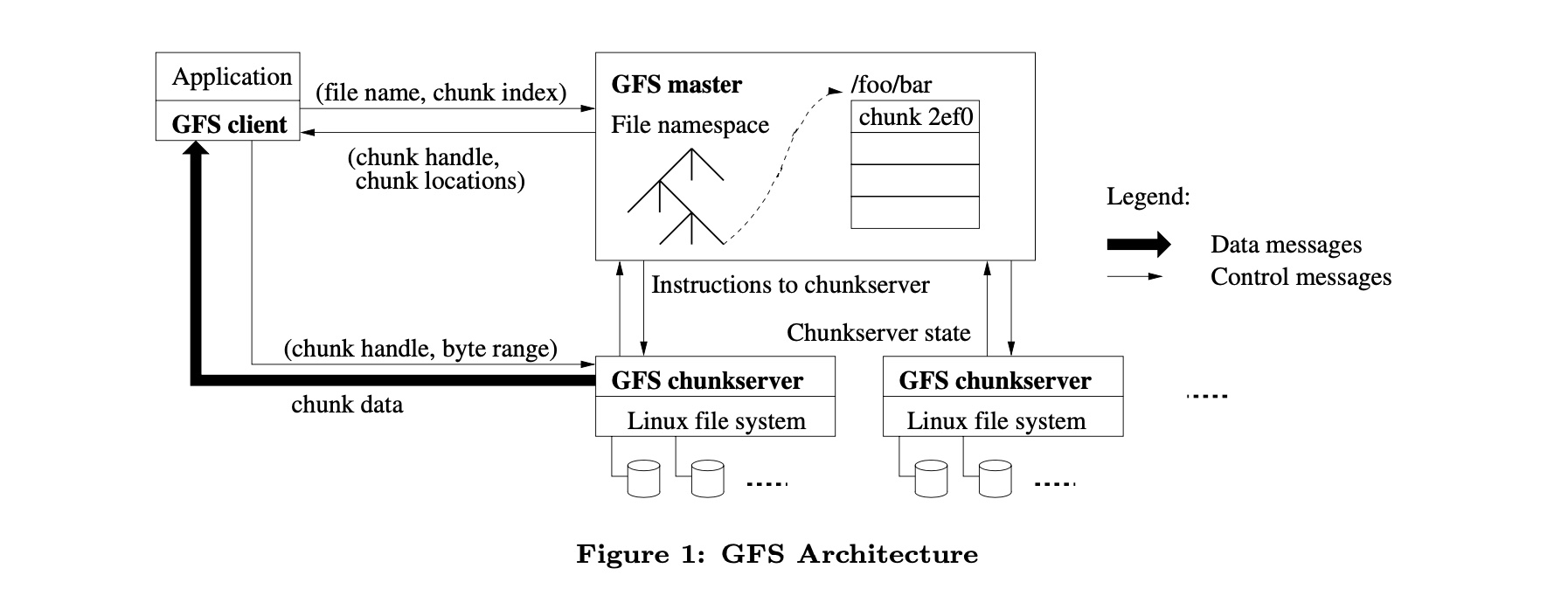
HDFS 1.0中的角色划分:
NameNode:对应论文中的GFS master,NN维护整个文件系统的文件目录树,文件目录的元信息和文件数据块索引;元数据镜像FsImage和操作日志EditLog存储在本地,但整个系统存在单点问题,存在SPOF(Simple Point Of Filure)。SecondNameNode:又名CheckPoint Node用于定期合并FsImage和EditLog文件,其不接收客户端的请求,作为NameNode的冷备份。DataNode:对应GFS中的chunkserver,实际的数据存储单元(以Block为单位),数据以普通文件形式保存在本地文件系统。Client:与HDFS交互,进行读写、创建目录、创建文件、复制、删除等操作。HDFS提供了多种客户端,命令行shell、Java api、Thrift接口、C library、WebHDFS等。
HDFS的chunk size大小为64MB,这比大多数文件系统的block大小要大。较大的block size优势在于,在获取块位置信息时候,减少了client与NameNode交互的次数。其次,由于在大的block上,客户端更有可能在给定块上执行许多操作,可以与NameNode保持一个长时间的TCP连接来减少网络开销。第三,减少了存储在NameNode上的元数据的大小,这就可以使得NameNode将元数据信息保存在Memory中。
HDFS Metadata元数据信息
GFS论文中Master节点中存储了三种元数据信息:文件和数据块的namespace、从files文件到chunkserver的映射关系及chunk副本数据位置。前两种数据是通过EditLog存储在本地磁盘的,而chunk location则是在Master启动时向chunk server发起请求进行获取。
一个大文件由多个Data Block数据集合组成,每个数据块在本地文件系统中是以单独的文件存储的。谈谈数据块分布,默认布局规则(假设复制因子为3):
- 第一份拷贝写入创建文件的节点(快速写入数据);
- 第二份拷贝写入同一个
rack内的节点; - 第三份拷贝写入位于不同
rack的节点(应对交换机故障);
HDFS写流程,对于大文件,与HDFS客户端进行交互,NN告知客户端第一个Block放在何处?将数据块流式的传输到另外两个数据节点。FsImage和EditLog组件的目的:
NameNode的内存中有整个文件系统的元数据,例如目录树、块信息、权限信息等,当NameNode宕机时,内存中的元数据将全部丢失。为了让重启的NameNode获得最新的宕机前的元数据,才有了FsImage和EditLog。FsImage是整个NameNode内存中元数据在某一时刻的快照(Snapshot),FsImage不能频繁的构建,生成FsImage需要花费大量的内存,目前FsImage只在NameNode重启才构建。- 而
EditLog则记录的是从这个快照开始到当前所有的元数据的改动。如果EditLog太多,重放EditLog会消耗大量的时间,这会导致启动NameNode花费数小时之久。
为了解决以上问题,引入了Second NameNode组件,我们需要一个机制来帮助我们减少EditLog文件的大小和构建fsimage以减少NameNode的压力。这与windows的恢复点比较像,允许我们对OS进行快照。
HDFS数据读写流程
HDFS设计目标是减少Master参与各种数据操作,在这种背景下,描述一下client、master和chunkserver如何进行交互来实现数据交互、原子性记录追加。
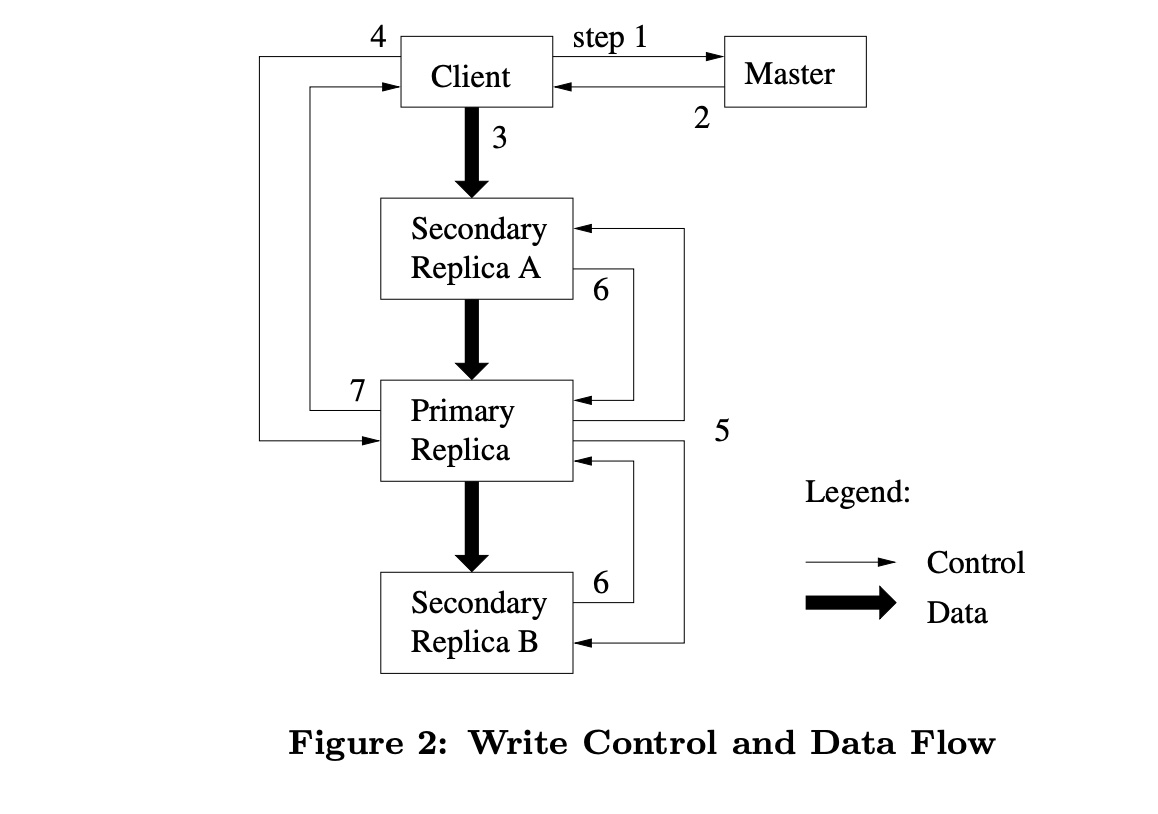
client向master发起请求询问哪个chunkserver持有当要写入的块及当前数据块的副本位置?master用primary标识符以及对应副本位置返回给client以进行cache(失效后会再次向master发起请求);client将数据写入到所有的副本中(不分先后顺序),每个chunkserver都会将数据写入内部的LRU buffer中直到数据被访问或过期;- 一旦所有的副本确认已经收到了数据,
client会发送一个write request到primary,说明之前的数据已完全写入完成。primary replica会返回一个连续的流水号给client; primary replica将write请求转发到所有的副本,每一个副本按照serial number的顺序执行变更,所有副本给primary返回结果则表示它们已经完成了操作。primary将信息返给client,包括replica在执行操作时发生的error。
DataFlow数据流转的过程,data是被线性的在一系列的chunkserver之间进行推送,而不是其它那些通过topology进行分发。这样做是为了尽量地避免network bottlenecks及high-latency links问题。举个例子,client推送数据到chunkserver S1, S1会将数据推送给离它最近的chunkserver S2或S3。本质是通过IP address之间距离来判断,network之间的hops。此外,数据的传输是通过TCP连接来完成的,一旦chunkserver收到一些数据,它会立刻进行数据转发。
Hadoop 2.0对HDFS的改进
Hdfs 1.0的问题:NameNode SPOF问题,NameNode挂掉了整个集群不可用,此外,Name Node内存受限,整个集群的size受限于NameNode的内存空间。Hadoop 2.0的解决方案,HDFS HA提供名称节点热备机制,HDFS Federation管理多个命名空间。
NameNode HA设计思路
- 如何实现主和备
NameNode状态同步,主备一致性? - 脑裂的解决,集群产生了两个
leader导致集群行为不一致,仲裁以及fencing的方式。 - 透明切换(
failover),NameNode切换对外透明,当主NameNode切换到另一台机器时,不应该导致正在连接的Client,DataNode失效。
- 对于
NameNode主备一致实现,Active NameNode启动后提供服务,并把EditLog写入到本地和QJM*中,Standby NameNode周期性的从QJM中拉取EditLog,保持与active的状态一致。DataNode同时向两个NameNode发送BlockReport。 HA之脑裂的解决,QJM的fencing,确保只有一个NN能成功。DataNode的fencing,确保只有一个NN能命令DN。每个NN改变状态的时候,会向DN发送自己的状态和一个序列号(类似Epoch Numbers)。当收到NN提供了更大序列号时,DN更新序列号,之后只接收新NN的命令。- 主备切换的实现
ZKFC,作为独立的进程存在,负责控制NameNode的主备切换,ZKFC会监测NameNode的健康状况,当Active NameNode出现异常时会通过Zookeeper集群进行一次主备选举。