谈谈我所了解的前端技术的发展
22 Apr 2025为什么会突然提到这个话题?
最近看到一个很好看的小程序前端模版nxdc-milktea,展示效果如下图所示,想着看把程序跑起来。看了前端代码仓库中有App.vue,我理解应该是基于vue开发的项目,但此项目没有package.json,按vue的方式启动不了。
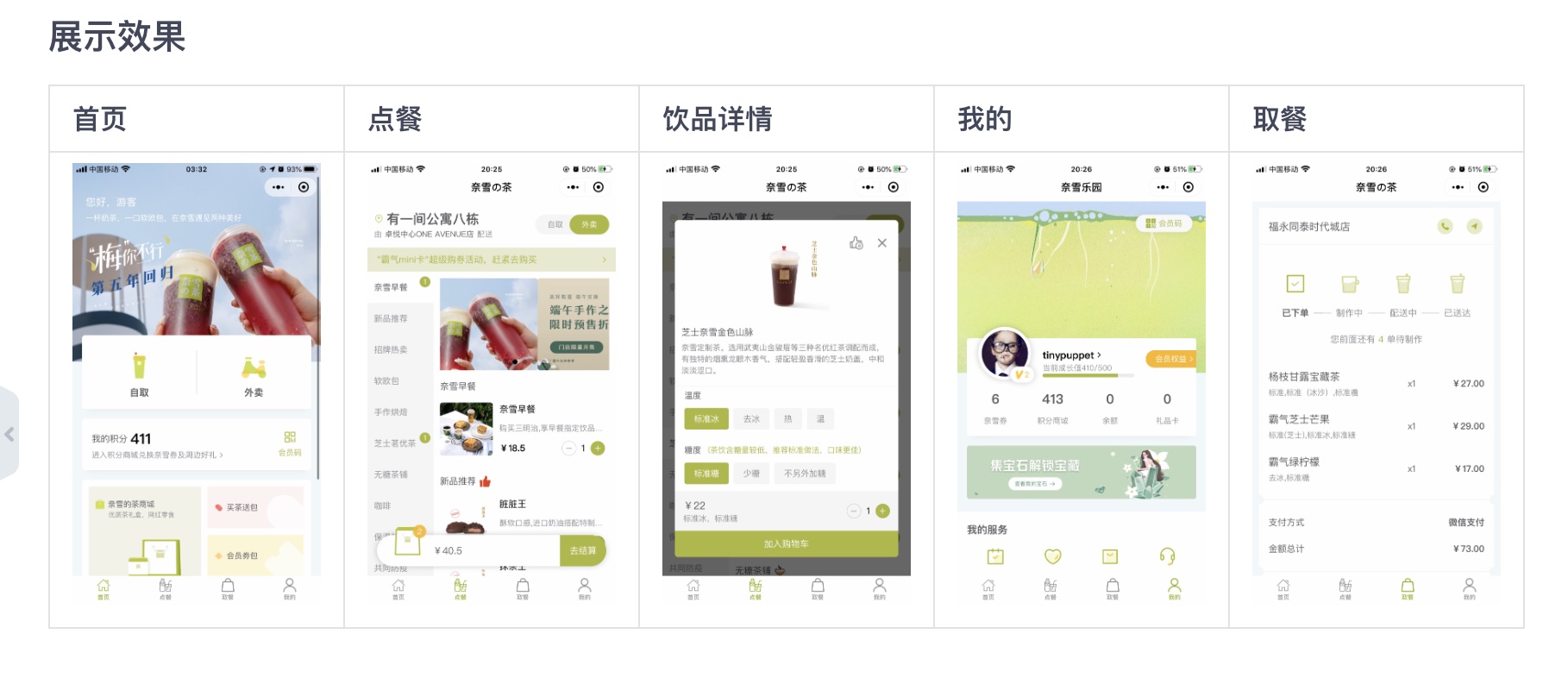
最近看到一个很好看的小程序前端模版nxdc-milktea,展示效果如下图所示,想着看把程序跑起来。看了前端代码仓库中有App.vue,我理解应该是基于vue开发的项目,但此项目没有package.json,按vue的方式启动不了。
nginx用docker安装nginx服务安装,我是用docker安装的,mac系统编译nginx源码安装有点问题。
docker pull nginx # 从docker仓库拉取nginx镜像
# nginx目录挂载参考此文章,https://blog.csdn.net/baidu_21349635/article/details/102738972
docker run --name nginx-0807 -v /Users/madong/software/nginx/nginx.conf:/etc/nginx/nginx.conf \
-v /Users/madong/software/nginx/conf.d:/etc/nginx/conf.d \
-v /Users/madong/software/nginx/html:/usr/share/nginx/html \
-v /Users/madong/software/nginx/logs:/var/log/nginx -p 8080:80 -d nginx
# nginx服务验证,curl有返回html内容时,则表示nginx服务启动成功了; /etc/nginx存nginx配置、/usr/share/nginx存在html、/var/log/nginx/存放nginx的access_log
curl 'http://localhost:8080/'
nginx也支持热更新,当修改nginx配置后,可使用nginx -s reload使修改的配置生效,当access.log文件特别大时,可使用nginx -s reopen切割日志。
Go语言相比Java,有更好的并发能力(GMP模型),同时其占用的服务器资源也较少,了解一下GMP的理念。从操作系统层面来看,线程是指内核级线程,是操作系统最小调度单元,创建、销毁、调度交由内核完成,可充分利用多核。协程(用户线程)与线程存在M:1的映射关系,从属于同一个内存级线程,无法并行,并且,一个协程阻塞会导致从属同一线程的所有协程无法执行。
经Golang优化后的协程,其有如下特点:1)与线程存在映射关系,为M:N;2)创建、销毁、调度在用户态完成,对内核透明,足够轻便;3)可利用多个线程,实现并行;4)通过调度器的斡旋,实现和线程间的动态绑定和灵活调度;5)栈空间大小可动态扩缩,因地制宜;
在/runtime/proc.go的代码注释中,有对GMP的解释,其核心数据结构在/runtime/runtime2.go:
database/sql/driver/driver.go关于数据库驱动模块下各核心interface主要包括:
Connector: 抽象的数据库连接器,需要具备创建数据库连接以及返回从属的数据库驱动的能力;Driver: 抽象的数据库驱动,具备创建数据库连接的能力;Conn: 抽象的数据库连接,具备预处理sql以及开启事务的能力;Tx: 抽象的事务,具备提交和回滚的能力;Statement: 抽象的请求预处理状态. 具备实际执行sql并返回执行结果的能力;Result/Row: 抽象的sql执行结果;
在极客时间上学习elasticsearch课程,主要关注点在query的DSL语句以及集群的管理,在本地基于es 7.1来构建集群服务,启动脚本如下,同时在conf/elasticsearch.yml中添加xpack.ml.enabled: false、http.host: 0.0.0.0的配置(禁用ml及启用host):
bash> bin/elasticsearch -E node.name=node0 -E cluster.name=geektime -E path.data=node0_data -d
bash> bin/elasticsearch -E node.name=node1 -E cluster.name=geektime -E path.data=node1_data -d
bash> bin/elasticsearch -E node.name=node2 -E cluster.name=geektime -E path.data=node2_data -d
bash> bin/elasticsearch -E node.name=node3 -E cluster.name=geektime -E path.data=node3_data -d
在docker容器中启动cerebro服务,用于监控elasticsearch集群的状态,docker启动命令如下:
bash> docker run -d --name cerebro -p 9100:9000 lmenezes/cerebro:latest